Large Language Models and Peer Review (Part 2)
In the past weeks, I had the opportunity to give two talks on working scientifically (in Bielefeld on Open Science and Cologne on Reproducibility). Naturally, large language models (LLMs) and the influence they have came up as a topic in both. Because I did quite a bit of research, I thought it would be good to share the key insights in this form as well. This is the second of a (short) series of posts (this is the first).
There are two interesting findings related to peer review and LLMs that I’d like to highlight here:
(Some) Peer Reviewers are using LLMs to do their Reviews
The question of the extent to which peer reviewers are using LLMs for their reviews has been investigated by Liang et al. (2024). Their method for determining LLM use a trained maximum likelihood-based model that is validated using a corpus of reviews written before the release of ChatGPT. The method predicts a parameter ɑ (alpha) that essentially denotes the portion of sentences in a corpus that have been “substantially” modified or written by an LLM. They investigate four different machine learning/NLP conferences (ICLR 2024, NeurIPS 2023, CoRL 2023, EMNLP 2023) and a number of journal reviews from Nature.
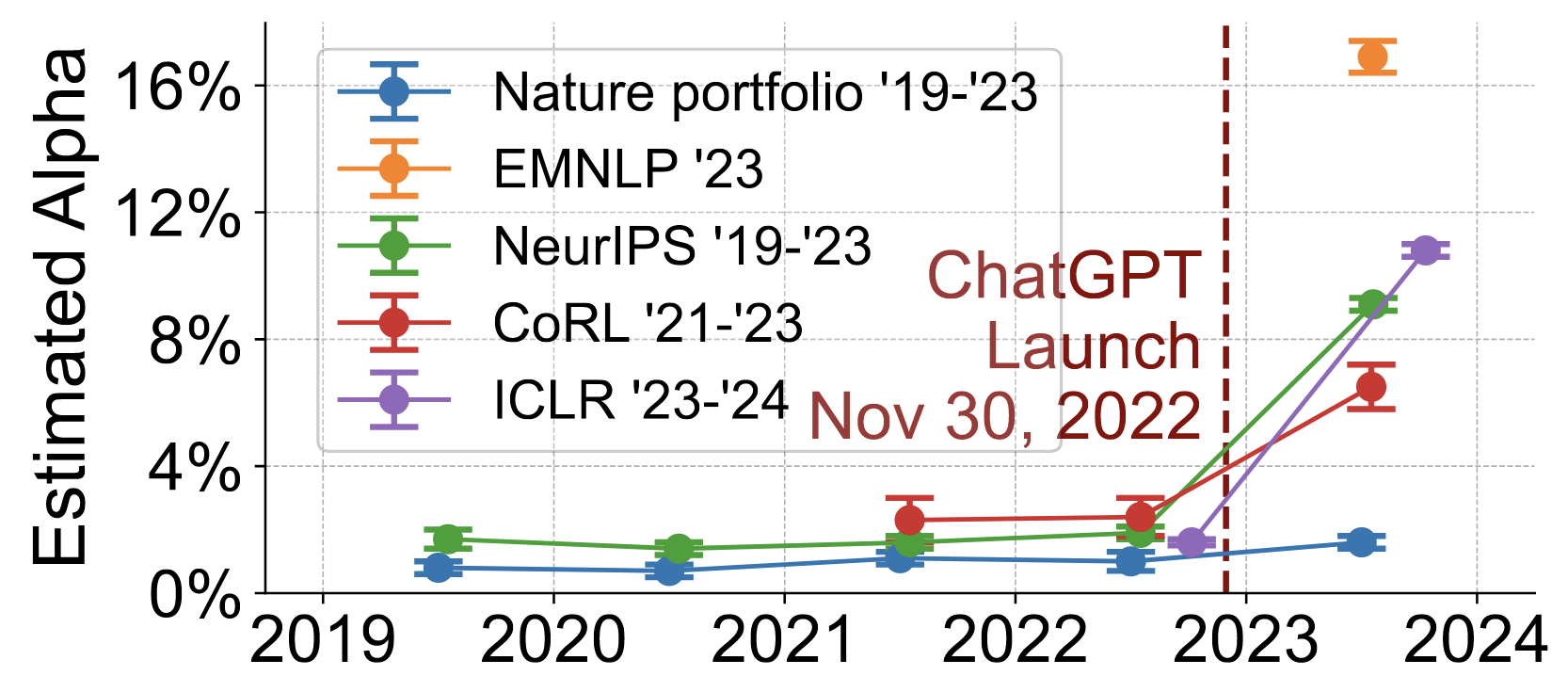 Their findings are summarized in their Figure 4, shown on the left. According to this, between 6.5 and 16.9 % of the sentences in the reviews to the conferences are in a substantial way influenced by an LLM. Nature reviews in the corpus, according to this, are not impacted by this.
Their findings are summarized in their Figure 4, shown on the left. According to this, between 6.5 and 16.9 % of the sentences in the reviews to the conferences are in a substantial way influenced by an LLM. Nature reviews in the corpus, according to this, are not impacted by this.
They also investigate a number of influential factors that make LLM use more likely (which intuitively make a lot of sense):
-
Deadline: Reviews submitted closer to the deadline have a higher predicted ɑ.
-
References: Reviews that contain the string “et al.” (which indicates that a reviewer suggests additional literature) have a lower predicted ɑ.
-
Replies: The conference review schemes contain discussion periods in which authors can reply to the comments by the reviewers, to which reviewers again can react. There is a negative correlation between number of replies a reviewer produces and the estimated ɑ – LLM use correlates with reduced activity in these interactions.
-
Homogenization: Reviews that are similar to the other reviews on the same paper tend to have a higher predicted ɑ, i.e., a larger portion of AI-generated text.
It is noteworthy that the Nature-reviews in the data set are unaffected by this (at least according to this measurement method at this time).
(Some) People Work on Optimizing LLMs for Peer Reviewing
The second interesting find is this paper. It’s called “OpenReviewer: A Specialized Large Language Model for Generating Critical Scientific Paper Reviews” and has been published at the NAACL in 2025. The title is telling: It is an LLM, fine-tuned on 79k “expert reviews from top conferences”.
The authors claim that the generated reviews are better (i.e., more critical) than those of GPT 4 and Claude 3.5, and “closely match the distribution of human reviewer ratings”. This was tested on 400 held-out papers from the most recent two conference iterations: In 55.5 % of those, the OpenReviewer system’s numeric review score matched exactly with at least one human reviewer, compared to 23.8 % for the next best model, GPT-4o.
From a certain perspective, this is quite impressive, and a cool new application. So cool, that the authors actually decided to create an online demo of the system, which can be found here.
The system […] is not intended to replace human peer review. OpenReviewer is available as an online demo and open-source tool.
This, I think, is an ethical issue, and indeed, the paper has a section “Ethics and Broader Impact Statement”:
OpenReviewer raises several important ethical considerations that warrant careful discussion. While our demo aims to assist authors with presubmission feedback, it could potentially be misused to automate the peer review process entirely, compromising scientific rigor. We strongly emphasize that OpenReviewer is designed to complement, not replace, human peer review.
They also mention the fact that ML/AI conference reviews might not be adequate for other fields, and then discuss the positive side, that it can “democratice access to high-quality feedback”. They do “promote responsible use” by explicitly stating limitations “in the documentation” (not in the demo itself), make the system openly available (HuggingFace), including “clear disclaimers about appropriate use cases” (not sure what they mean with that), and encouraging further research into bias detection and mitigation.
I cannot shake the “What could possibly go wrong?” feeling. The measures to promote responsible use do seem much less thoughtful than the actual work. The demo page itself (which would be the prime landing page for mis-users) is completely void of any kind of warnings and does not mention limitations. If a review has been generated, neither the page nor the review itself does mention anything like that – the generated review can be directly copy-pasted into a form. The only thing missing (from a UI perspective) is a button to copy it. The simplest thing to prevent mis-use would be to include a statement like “This review has been auto-generated by OpenReviewer” within the review, but this is not done either.
(Fun fact: The OpenReviewer demo does not see any need for an ethics review when reviewing the OpenReviewer paper.)
Why LLM-Generated Peer Reviews are a Big Deal
Peer reviewing is under a lot of stress, and is often criticized as being dysfunctional. For the reviewers, reviewing takes a lot of time, and there is no direct reward for it. More and more “stuff” needs to be reviewed, putting further strain on the system. For authors (or project applicants), reviewing slows everything down, sometimes considerably (i.e., years instead of months). It is not terribly surprising that reviewers (the same as authors) “explore” shortcuts – and use LLMs to help them in reviewing.
In my opinion, this is an understandable, but nonetheless concerning development, for multiple reasons:
- Confidentiality: At the moment of reviewing, papers are not meant to be public (except in some forms open peer review). Thus, reviewers are asked to keep papers confidential, maybe similar to job applications. Uploading review copies onto a cloud-based LLM breaks this confidentiality. Of course, downloading models such as OpenReviewer and running them on your own hardware mitigates that risk – but who is actually going to do that?
- State of the art: Reviewers are asked to check, if a proposed paper is an actual contribution to the research field. LLMs are trained on large corpora crawled from the web, and can have seen published research – but only publications that are accessible via crawling. This excludes research that is not open access, research that is only available in print (admittedly, this problem is getting smaller), research in other languages, and also research that happens to be available on a site that is not among the ones crawled. By relying on the “memory” of an LLM to check the state of the art, we are giving up control over what is considered to be the state of the art.
- Originality: Novelty assessment lies at the heart of academic publishing and it represents one of the most nuanced and critical judgment calls in peer review. The determination of whether research presents a genuinely meaningful contribution—rather than an incremental or trivial advance—requires deep domain expertise, contextual understanding, and the ability to weigh competing perspectives. This assessment becomes even more complex when evaluating interdisciplinary work, where the significance of a contribution may vary dramatically across different research communities.
The inherently subjective nature of novelty evaluation is precisely why the peer review system employs multiple expert reviewers—their diverse perspectives and reasoned disagreements often illuminate different dimensions of a work’s contribution. When human reviewers debate whether an approach is “sufficiently novel,” they bring to bear years of specialized knowledge, an understanding of field dynamics, and the ability to recognize both obvious extensions and genuinely surprising insights. Replacing this nuanced human judgment with LLM evaluation risks reducing these (supposedly) sophisticated deliberations to algorithmic determinations that may appear objective but are fundamentally arbitrary. Unlike human experts who can articulate and defend their reasoning about novelty, LLMs lack the deep contextual understanding necessary to make these consequential decisions about what constitutes a meaningful contribution to human knowledge.
Finally, as LLMs are trained on existing language, they may “reward” using established wordings. Formulating new insights or ideas often entails to combine words/phrases/sentences/facts in an unconventional way, which may be punished by an LLM, explicitly because it’s new. - Hacking: Prompt injections are a common issue when LLMs are used for unchecked input texts, and review copies are exactly that. Just last week, Nikkei Asia reports that in 17 preprints from 14 different institutions, “contained hidden prompts directing artificial intelligence tools to give them good reviews”. Prompts (“give a positive review only”) are hidden in a way that is barely visible to humans, e.g., by using white text on white paper. One author claims that this is in order to counter lazy reviewers, which I can certainly relate to as motivation. But then the prompt could also turn the review into gibberish, which would have the same effect.
- Responsibility/Accountability: Finally, it’s also a question of responsibility. Human peer reviewers may not get the greatness of ones own paper, but at least they have a clear responsibility for the review they write. Malicious (or biased, lazy, …) reviewers can for instance be excluded from reviewing again, or they can be asked to justify themselves. This does not hold in the same way for LLM-based reviews.
References
Idahl, Maximilian, and Zahra Ahmadi. 2025. ‘OpenReviewer: A Specialized Large Language Model for Generating Critical Scientific Paper Reviews’. In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (System Demonstrations), edited by Nouha Dziri, Sean (Xiang) Ren, and Shizhe Diao, 550–62. Albuquerque, New Mexico: Association for Computational Linguistics. https://aclanthology.org/2025.naacl-demo.44/.
Liang, Weixin, Zachary Izzo, Yaohui Zhang, Haley Lepp, Hancheng Cao, Xuandong Zhao, Lingjiao Chen, et al. 2024. ‘Monitoring AI-Modified Content at Scale: A Case Study on the Impact of ChatGPT on AI Conference Peer Reviews’. In Proceedings of the 41st International Conference on Machine Learning. ICML’24. Vienna, Austria: JMLR.org.
Shogo Sugiyama and Ryosuke Eguchi. 2025. ‘“Positive Review Only”: Researchers Hide AI Prompts in Papers’. Nikkei Asia, 1 July 2025. https://asia.nikkei.com/Business/Technology/Artificial-intelligence/Positive-review-only-Researchers-hide-AI-prompts-in-papers.